In part 1, we had some awk code that could parse the stat file and show the PNUMs with the source and destination servers and file names, tab delimited.
To illustrate why anybody would be interested in doing this, here is what some stats look like without a parse script: 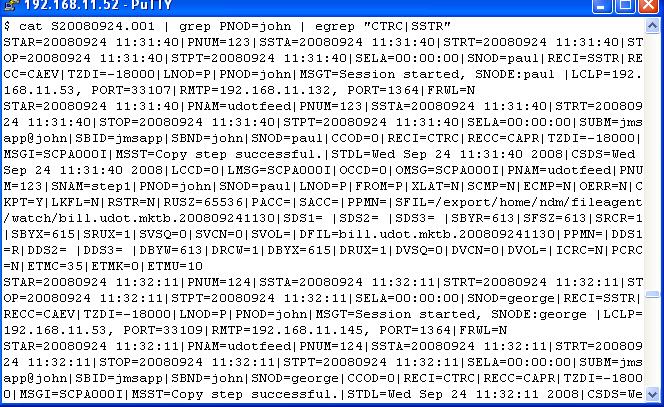
Not very convenient to gather information from, especially if you have thousands of transmissions and detailed analysis to do. Let's add some features to the awk code from part 1. First, we can wrap the awk into a shell script, and accept the fields we want on the command line. Some fields, such as RMTP, may have equal signs in the values. Since we are splitting on equal signs we need to put the values back together, so let's fix that, also.
#!/bin/ksh
PATH=/usr/xpg4/bin:/usr/bin
# default field IDs
FIELDIDS=PNUM,PNOD,SNOD,SFIL,DFIL,CCOD
# get different field IDs from command line, if they are specified
if [ "$1" = "-f" -a -n "$2" ]; then
FIELDIDS=$2
fi
PATH=/usr/xpg4/bin:/usr/bin
# default field IDs
FIELDIDS=PNUM,PNOD,SNOD,SFIL,DFIL,CCOD
# get different field IDs from command line, if they are specified
if [ "$1" = "-f" -a -n "$2" ]; then
FIELDIDS=$2
fi
awk -F"|" '{
# populate array B with all values using field names as subscripts
for (i=1;i<=NF;i++) {
SS=split($i,A,"=");SUB=A[1]; B[SUB]=A[2];delete A[1];delete A[2]
# if the field has a second = in it, that means $i was split
# into more than 2 pieces, gather the pieces
for (j=3;j<=SS;j++) {
B[SUB]=B[SUB]"="A[j];delete A[j]
}
}
# go through all the fields requested and show values
NE=split(FIELDIDS,F,",")
for (IX=1;IX<=NE;IX++) {
FLD=F[IX]
printf "%s\t",B[FLD]
delete F[IX]
}
print ""
# clear array B
for (SUB in B) delete B[SUB]
}' FIELDIDS=$FIELDIDS -
# populate array B with all values using field names as subscripts
for (i=1;i<=NF;i++) {
SS=split($i,A,"=");SUB=A[1]; B[SUB]=A[2];delete A[1];delete A[2]
# if the field has a second = in it, that means $i was split
# into more than 2 pieces, gather the pieces
for (j=3;j<=SS;j++) {
B[SUB]=B[SUB]"="A[j];delete A[j]
}
}
# go through all the fields requested and show values
NE=split(FIELDIDS,F,",")
for (IX=1;IX<=NE;IX++) {
FLD=F[IX]
printf "%s\t",B[FLD]
delete F[IX]
}
print ""
# clear array B
for (SUB in B) delete B[SUB]
}' FIELDIDS=$FIELDIDS -
I name this script parse. Now let's use it to show the stats. This shows me a neat, tab-delimited list of what files I transmitted outbound yesterday, with destination node name and IP, filenames, and completion codes:
$ cat S20080924.001 |grep PNOD=john |egrep "CTRC|SSTR" |parse -f PNUM,RECI,SNOD,DFIL,RMTP,CCOD
123 SSTR paul 192.168.11.132, PORT=1364
123 CTRC paul bill.udot.mktb.200809241130 0
124 SSTR george 192.168.11.145, PORT=1364
124 CTRC george bill.udot.mktb.200809241130 0
125 SSTR paul 192.168.11.132, PORT=1364
125 CTRC paul bill.udot.mkta.200809241137 0
126 SSTR george 192.168.11.145, PORT=1364
126 CTRC george bill.udot.mkta.200809241137 0
127 SSTR paul 192.168.11.132, PORT=1364
127 CTRC paul bill.udot.mkta.200809241153 0
128 SSTR george 192.168.11.145, PORT=1364
128 CTRC george bill.udot.mkta.200809241153 0
129 SSTR paul 192.168.11.132, PORT=1364
129 CTRC paul bill.udot.mktb.200809241156 0
130 SSTR george 192.168.11.145, PORT=1364
130 CTRC george bill.udot.mktb.200809241156 0
131 SSTR paul 192.168.11.132, PORT=1364
131 CTRC paul bill.udot.mktb.200809241230 0
132 SSTR george 192.168.11.145, PORT=1364
132 CTRC george bill.udot.mktb.200809241230 0
133 SSTR paul 192.168.11.132, PORT=1364
133 CTRC paul bill.udot.mkta.200809241237 0
134 SSTR george 192.168.11.145, PORT=1364
134 CTRC george bill.udot.mkta.200809241237 0
135 SSTR paul 192.168.11.132, PORT=1364
135 CTRC paul bill.udot.mkta.200809241253 0
136 SSTR george 192.168.11.145, PORT=1364
136 CTRC george bill.udot.mkta.200809241253 0
137 SSTR paul 192.168.11.132, PORT=1364
137 CTRC paul bill.udot.mktb.200809241256 0
138 SSTR george 192.168.11.145, PORT=1364
138 CTRC george bill.udot.mktb.200809241256 0
139 SSTR paul 192.168.11.132, PORT=1364
139 CTRC paul todtrigger.200809241722.input 0
140 SSTR paul 192.168.11.132, PORT=1364
140 CTRC paul todtrigger.200809241723.input 0
141 SSTR paul 192.168.11.132, PORT=1364
141 CTRC paul todtrigger.200809241724.input 0
142 SSTR paul 192.168.11.132, PORT=1364
142 CTRC paul todtrigger.200809241725.input 0
143 SSTR paul 192.168.11.132, PORT=1364
143 CTRC paul todtrigger.200809241726.input 0
144 SSTR paul 192.168.11.132, PORT=1364
144 CTRC paul todtrigger.200809241727.input 0
123 SSTR paul 192.168.11.132, PORT=1364
123 CTRC paul bill.udot.mktb.200809241130 0
124 SSTR george 192.168.11.145, PORT=1364
124 CTRC george bill.udot.mktb.200809241130 0
125 SSTR paul 192.168.11.132, PORT=1364
125 CTRC paul bill.udot.mkta.200809241137 0
126 SSTR george 192.168.11.145, PORT=1364
126 CTRC george bill.udot.mkta.200809241137 0
127 SSTR paul 192.168.11.132, PORT=1364
127 CTRC paul bill.udot.mkta.200809241153 0
128 SSTR george 192.168.11.145, PORT=1364
128 CTRC george bill.udot.mkta.200809241153 0
129 SSTR paul 192.168.11.132, PORT=1364
129 CTRC paul bill.udot.mktb.200809241156 0
130 SSTR george 192.168.11.145, PORT=1364
130 CTRC george bill.udot.mktb.200809241156 0
131 SSTR paul 192.168.11.132, PORT=1364
131 CTRC paul bill.udot.mktb.200809241230 0
132 SSTR george 192.168.11.145, PORT=1364
132 CTRC george bill.udot.mktb.200809241230 0
133 SSTR paul 192.168.11.132, PORT=1364
133 CTRC paul bill.udot.mkta.200809241237 0
134 SSTR george 192.168.11.145, PORT=1364
134 CTRC george bill.udot.mkta.200809241237 0
135 SSTR paul 192.168.11.132, PORT=1364
135 CTRC paul bill.udot.mkta.200809241253 0
136 SSTR george 192.168.11.145, PORT=1364
136 CTRC george bill.udot.mkta.200809241253 0
137 SSTR paul 192.168.11.132, PORT=1364
137 CTRC paul bill.udot.mktb.200809241256 0
138 SSTR george 192.168.11.145, PORT=1364
138 CTRC george bill.udot.mktb.200809241256 0
139 SSTR paul 192.168.11.132, PORT=1364
139 CTRC paul todtrigger.200809241722.input 0
140 SSTR paul 192.168.11.132, PORT=1364
140 CTRC paul todtrigger.200809241723.input 0
141 SSTR paul 192.168.11.132, PORT=1364
141 CTRC paul todtrigger.200809241724.input 0
142 SSTR paul 192.168.11.132, PORT=1364
142 CTRC paul todtrigger.200809241725.input 0
143 SSTR paul 192.168.11.132, PORT=1364
143 CTRC paul todtrigger.200809241726.input 0
144 SSTR paul 192.168.11.132, PORT=1364
144 CTRC paul todtrigger.200809241727.input 0
What if I wanted to clean up this output a little bit more? I really just wanted the destination IP address, but the RMTP field has the IP address and port number in it, and a comma. This is where we can derive fields from existing information inside other fields.
#!/bin/ksh
PATH=/usr/xpg4/bin:/usr/bin
# default field IDs
FIELDIDS=PNUM,PNOD,SNOD,SFIL,DFIL,CCOD
# get different field IDs from command line, if they are specified
if [ "$1" = "-f" -a -n "$2" ]; then
FIELDIDS=$2
fi
PATH=/usr/xpg4/bin:/usr/bin
# default field IDs
FIELDIDS=PNUM,PNOD,SNOD,SFIL,DFIL,CCOD
# get different field IDs from command line, if they are specified
if [ "$1" = "-f" -a -n "$2" ]; then
FIELDIDS=$2
fi
awk -F"|" '{
# populate array B with all values using field names as subscripts
for (i=1;i<=NF;i++) {
SS=split($i,A,"=");SUB=A[1]; B[SUB]=A[2];delete A[1];delete A[2]
# if the field has a second = in it, that means $i was split
# into more than 2 pieces, gather the pieces
for (j=3;j<=SS;j++) {
B[SUB]=B[SUB]"="A[j];delete A[j]
}
}
# go through all the fields requested and show values
NE=split(FIELDIDS,F,",")
for (IX=1;IX<=NE;IX++) {
FLD=F[IX]
if (FLD=="LOCIP") {
split(B["LCLP"],A,",")
B["LOCIP"]=A[1]
delete A[1]; delete A[2]
}
if (FLD=="LOCPORT") {
split(B["LCLP"],A,"=")
B["LOCPORT"]=A[2]
delete A[1]; delete A[2]
}
if (FLD=="RMTIP") {
split(B["RMTP"],A,",")
B["RMTIP"]=A[1]
delete A[1]; delete A[2]
}
if (FLD=="RMTPORT") {
split(B["RMTP"],A,"=")
B["RMTPORT"]=A[2]
delete A[1]; delete A[2]
}
printf "%s\t",B[FLD]
delete F[IX]
}
print ""
# clear array B
for (SUB in B) delete B[SUB]
}' FIELDIDS=$FIELDIDS -
# populate array B with all values using field names as subscripts
for (i=1;i<=NF;i++) {
SS=split($i,A,"=");SUB=A[1]; B[SUB]=A[2];delete A[1];delete A[2]
# if the field has a second = in it, that means $i was split
# into more than 2 pieces, gather the pieces
for (j=3;j<=SS;j++) {
B[SUB]=B[SUB]"="A[j];delete A[j]
}
}
# go through all the fields requested and show values
NE=split(FIELDIDS,F,",")
for (IX=1;IX<=NE;IX++) {
FLD=F[IX]
if (FLD=="LOCIP") {
split(B["LCLP"],A,",")
B["LOCIP"]=A[1]
delete A[1]; delete A[2]
}
if (FLD=="LOCPORT") {
split(B["LCLP"],A,"=")
B["LOCPORT"]=A[2]
delete A[1]; delete A[2]
}
if (FLD=="RMTIP") {
split(B["RMTP"],A,",")
B["RMTIP"]=A[1]
delete A[1]; delete A[2]
}
if (FLD=="RMTPORT") {
split(B["RMTP"],A,"=")
B["RMTPORT"]=A[2]
delete A[1]; delete A[2]
}
printf "%s\t",B[FLD]
delete F[IX]
}
print ""
# clear array B
for (SUB in B) delete B[SUB]
}' FIELDIDS=$FIELDIDS -
Now we have additional derived fields to choose from, besides the regular fields inside the stat records.
$ cat S20080924.001 |grep PNOD=john |egrep "CTRC|SSTR" |parse -f PNUM,RECI,SNOD,DFIL,RMTIP,CCOD
123 SSTR paul 192.168.11.132
123 CTRC paul bill.udot.mktb.200809241130 0
124 SSTR george 192.168.11.145
124 CTRC george bill.udot.mktb.200809241130 0
125 SSTR paul 192.168.11.132
125 CTRC paul bill.udot.mkta.200809241137 0
126 SSTR george 192.168.11.145
126 CTRC george bill.udot.mkta.200809241137 0
127 SSTR paul 192.168.11.132
127 CTRC paul bill.udot.mkta.200809241153 0
128 SSTR george 192.168.11.145
128 CTRC george bill.udot.mkta.200809241153 0
129 SSTR paul 192.168.11.132
129 CTRC paul bill.udot.mktb.200809241156 0
130 SSTR george 192.168.11.145
130 CTRC george bill.udot.mktb.200809241156 0
131 SSTR paul 192.168.11.132
131 CTRC paul bill.udot.mktb.200809241230 0
132 SSTR george 192.168.11.145
132 CTRC george bill.udot.mktb.200809241230 0
133 SSTR paul 192.168.11.132
133 CTRC paul bill.udot.mkta.200809241237 0
134 SSTR george 192.168.11.145
134 CTRC george bill.udot.mkta.200809241237 0
135 SSTR paul 192.168.11.132
135 CTRC paul bill.udot.mkta.200809241253 0
136 SSTR george 192.168.11.145
136 CTRC george bill.udot.mkta.200809241253 0
137 SSTR paul 192.168.11.132
137 CTRC paul bill.udot.mktb.200809241256 0
138 SSTR george 192.168.11.145
138 CTRC george bill.udot.mktb.200809241256 0
139 SSTR paul 192.168.11.132
139 CTRC paul todtrigger.200809241722.input 0
140 SSTR paul 192.168.11.132
140 CTRC paul todtrigger.200809241723.input 0
141 SSTR paul 192.168.11.132
141 CTRC paul todtrigger.200809241724.input 0
142 SSTR paul 192.168.11.132
142 CTRC paul todtrigger.200809241725.input 0
143 SSTR paul 192.168.11.132
143 CTRC paul todtrigger.200809241726.input 0
144 SSTR paul 192.168.11.132
144 CTRC paul todtrigger.200809241727.input 0
123 CTRC paul bill.udot.mktb.200809241130 0
124 SSTR george 192.168.11.145
124 CTRC george bill.udot.mktb.200809241130 0
125 SSTR paul 192.168.11.132
125 CTRC paul bill.udot.mkta.200809241137 0
126 SSTR george 192.168.11.145
126 CTRC george bill.udot.mkta.200809241137 0
127 SSTR paul 192.168.11.132
127 CTRC paul bill.udot.mkta.200809241153 0
128 SSTR george 192.168.11.145
128 CTRC george bill.udot.mkta.200809241153 0
129 SSTR paul 192.168.11.132
129 CTRC paul bill.udot.mktb.200809241156 0
130 SSTR george 192.168.11.145
130 CTRC george bill.udot.mktb.200809241156 0
131 SSTR paul 192.168.11.132
131 CTRC paul bill.udot.mktb.200809241230 0
132 SSTR george 192.168.11.145
132 CTRC george bill.udot.mktb.200809241230 0
133 SSTR paul 192.168.11.132
133 CTRC paul bill.udot.mkta.200809241237 0
134 SSTR george 192.168.11.145
134 CTRC george bill.udot.mkta.200809241237 0
135 SSTR paul 192.168.11.132
135 CTRC paul bill.udot.mkta.200809241253 0
136 SSTR george 192.168.11.145
136 CTRC george bill.udot.mkta.200809241253 0
137 SSTR paul 192.168.11.132
137 CTRC paul bill.udot.mktb.200809241256 0
138 SSTR george 192.168.11.145
138 CTRC george bill.udot.mktb.200809241256 0
139 SSTR paul 192.168.11.132
139 CTRC paul todtrigger.200809241722.input 0
140 SSTR paul 192.168.11.132
140 CTRC paul todtrigger.200809241723.input 0
141 SSTR paul 192.168.11.132
141 CTRC paul todtrigger.200809241724.input 0
142 SSTR paul 192.168.11.132
142 CTRC paul todtrigger.200809241725.input 0
143 SSTR paul 192.168.11.132
143 CTRC paul todtrigger.200809241726.input 0
144 SSTR paul 192.168.11.132
144 CTRC paul todtrigger.200809241727.input 0
This makes a beautiful and almost effortless import into Excel for further analysis:
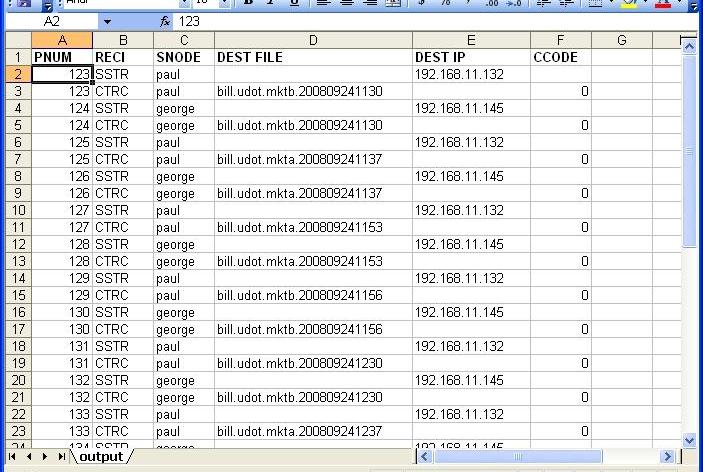
Note: In the previous posting's comments I mentioned that you should use nawk instead of awk in Solaris. In the script I put /usr/xpg4/bin in the PATH before /usr/bin. So, if you run this in Solaris it will pick the newer, standards-compliant version of awk, which is like nawk. On other systems such as HPUX or Linux, the extra directory in the PATH will be harmless, but the script will be portable.
