The UNIX utility uniq examines each line of text piped into it, and if the line is identical to the previous line, it skips displaying it. So if you pipe sorted text into it, you end up with a text file where every line is unique. No repeated lines. I want a uniq that examines each line of text piped into it, and if the line is similar to the previous line, it skips displaying it. I want to end up with a text file that gives one example line of each group of lines that are similar to each other. Well, I searched high and low, and if there is such a utility, I sure can't find it. I set out to make a script that I call funiq, for fuzzy uniq.
Requirement: Compare lines. Each line should be calculated to have a certain percentage of similarity compared to the line above. If the line is sufficiently similar to the line already displayed, don't display it and move on. I did a lot of searching on the Internet to try to find out how to calculate similarity. I ended up reading an interesting article here: http://www.catalysoft.com/articles/StrikeAMatch.html
The basic idea is to take two lines of input and split them up into character pairs. Throw out the character pairs that have spaces in them. Throw out empty lines. Count the number of character pairs in a line that match character pairs in the line below it. This is the intersection of the two character-pair sets. Apply a formula that computes two times the intersection divided by the total number of character pairs in both lines.
#!/bin/ksh
PATH=/usr/xpg4/bin:/usr/bin
# get percentage of similarity from -s command line option, or 85 for default
if [ "$1" = "-s" -a -n "$2" ]; then
SIM=$2
shift 2
else
SIM=85
fi
awk 'BEGIN {CURRPAIRS=0;PAIRMATCHES=0;PREVPAIRS=0}
{
# load array of character pairs for current comparison string
for (i=1;i<length($0);i++) {
CURR[i]=substr($0,i,2)
}
# remove character pairs that contain spaces
for (SUBC in CURR) {
if ( index(CURR[SUBC]," ") ) {
delete CURR[SUBC]
}
}
# count the number of character pairs in comparison string,
# and count matches compared to previous comparison string
CURRPAIRS=0
PAIRMATCHES=0
for (SUBC in CURR) {
CURRPAIRS++
for (SUBP in PREV) {
if (CURR[SUBC]==PREV[SUBP]) {
PAIRMATCHES++
# only count matches once
delete PREV[SUBP]
}
}
}
# remove empty lines from consideration by skipping to next line
if (CURRPAIRS==0) next
# compute similarity
SIM=200*PAIRMATCHES/(CURRPAIRS+PREVPAIRS)
# display output if not similar
if (REQSIM >= SIM) print $0
# move array of character pairs to store as previous string
for (SUB in PREV) delete PREV[SUB]
for (SUB in CURR) PREV[SUB]=CURR[SUB]
for (SUB in CURR) delete CURR[SUB]
PREVPAIRS=CURRPAIRS
}' REQSIM=$SIM $@
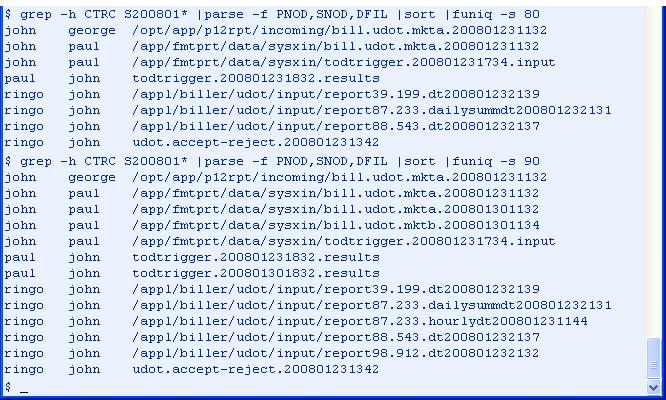
Command line option: the percentage of similarity can be specified by -s followed by a number between 0 and 100. The default is 85.
Sample data input for funiq (378 lines, not all shown):


1 comment:
fuzzy uniq, exactly what I was looking for the other day. Thanks!
Post a Comment